

By Benjamin Larson

Machine learning is an important tool in the “Data Analytics Toolkit.” What is it exactly and why is it so powerful? More importantly, how can I leverage it as an HTM professional?
In computer programming, you learn how to turn common tasks into logic based steps. You take a simple task and boil it down into a series of binary commands. You have to program every step and you have to have a rule in place to handle every possible exception. Computers can’t think for themselves.
Or can they?
With machine learning, computers make the rules. Instead of having a human program each step, machine learning is accomplished by feeding data through an algorithm. The algorithm then develops the programmatic logic and rules from data it is fed.
Machine learning comes in two flavors: Supervised and Unsupervised.
1. Supervised Machine Learning Example: Field Service Analysis
Supervised learning creates a function from a data set containing both input variables and a result. Consider a list of inputs for housing prices (square footage, garage, number of bathrooms). If you know the result (price the house sold for), you can easily develop a formula that can predict the selling price of a house.
Let’s say you manage a field service operation where you employ two levels of field engineers:
Tier 1 and Tier 2. Tier 1 engineers are junior, lower cost employees. Tier 2 are your senior engineers.
As a manager, you are constantly trying to strike a balance between customer satisfaction and the company’s bottom line. You are concerned that every time a Tier 1 engineer cannot complete a repair and has to call in a Tier 2 engineer, the customer experiences extended downtime. However, you don’t want to send Tier 2 engineer out to perform a job a less costly Tier 1 engineer could perform.
The answer: Logistic Regression
You put together a spreadsheet of all your repairs for the past two years, including information such as equipment type, age, model, location, repair history score. In the last column of your spreadsheet is your result (0 or 1), where 0 = Tier 1 completed the job, and 1 = Tier 2 had to be called in. You run this data through a logistic regression algorithm and it builds a model (an equation). Once this model is built, you can then feed your next repair call into your model, entering the input variables above. The output is a number between 0 and 1 representing the probability a Tier 2 technician will need to be called out to complete the job. (A 0.75 output means there is a 75 percent chance Tier 2 will need to be called out). Using this information, you can determine when to just send out a Tier 2 engineer in the first place.
The beauty of this model is that it continues to learn and improve. If you retrain the model with new data, it will adjust to changes and improve its accuracy. Maybe your Tier 1 engineers are getting better? Maybe some of the newer equipment is more complex and provides greater challenges?
The real world is not a static target. We rely on outdated information, because we lack the bandwidth needed to re-evaluate a metric. However, updating a machine learning model can be as simple as retraining the model with fresh data.
2. Unsupervised Machine Learning: Repair History Clustering
Unsupervised learning doesn’t look for an answer. Instead it groups information into like sets forbanalysis. It is a bit more of an art. Since the result is a grouping of like data, it is up to the analyst to make sense of the groupings and to draw inferences about the data from the groupings.
Let us take three years of ultrasound repair history. We compile this data into a spreadsheet and pass this spreadsheet through an unsupervised machine learning algorithm known as K-Means Clustering.
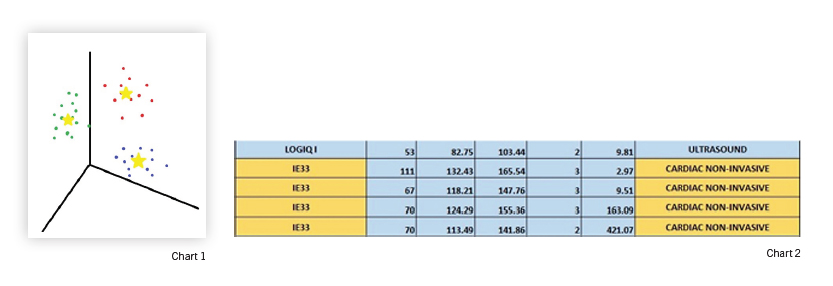
K-Means Clustering takes each row from your spreadsheet and converts them to a vector. It then maps the vectors out in space and uses something known as a geometric mean to see which ones seem to cluster together (see chart 1).
Each dot represents an Ultrasound machine. The dots are assigned a color based on their proximity to each other. The yellow stars represent the geometric mean for each cluster.
Using my data set of 300+ ultrasounds, the algorithm returned four clusters. Looking closely at the clusters, patterns quickly emerged. To help illustrate, I have a snippet from my fourth cluster (see chart2).
A quick glimpse into this cluster shows something interesting. A single department with four Philips IE33 ultrasounds managed to rack up 318 work orders in three years (that is a little over two a week). Checking the other clusters, I see that I have plenty of IE33 (66 to be exact) that do not appear to be problematic. I also note that this department has other ultrasounds that do not have nearly as many repair tickets.
Using the information provided and my experience in the field, I concluded the techs in this department do not know how to use the IE33. With a repair rate of twice a week, the cost of bringing in the vendor to retrain the department is easily justified.
Other clusters show information like high parts expenditures, above average labor minutes for repairs, and a high number of vendor repairs. Each cluster can provide you with actionable information.
While both of these examples are intentionally simplistic, they show the possibilities machine learning opens for the HTM profession. Data found in your computerized maintenance management system (CMMS) can provide insight and help your department improve its efficiency and cost effectiveness.
